Logistic Regression
Lab 7
Dr. Elijah Meyer
Duke University
STA 199 - Spring 2023
March 20th, 2023
Announcements
– Project proposal feedback coming (by end of week)
– The beginning of today’s lab shows you how to access and respond to feedback given for the project
Test vs Train
Recall from last lecture:
– A training data set is a data set used to build your model (“Sandbox”).
– A testing data set is a data set to evaluate your model
Normally, if our data are large, we split the data into 80% for training and 20% for testing
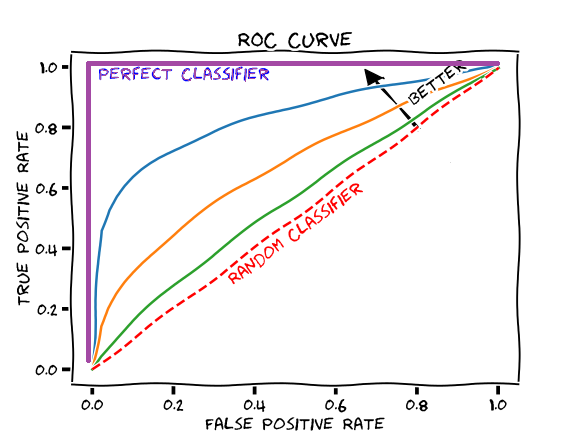
ROC Curve (What you need to know)
– Tool used to compare models by their predictive performance (ae-16)
– Compare the area under the curve (AUC) and select model that has the largest
The larger the area under the curve, the better our model is doing in correctly predicting our response in the testing data set
ROC Curve Extension (More in class Wednesday)
We will re-go over ROC curves to start class Wednesday to make sure everyone is on the same page + give a better explanation on how these are fit
– The ROC curve is fit by calculating sensitivity and specificity at a number of decision thresholds in-between 0 and 1
– Besides helping select a model, this can be used to gain information about what an appropriate threshold to use is
— This information is in the roc_curve function
Things to note
– AIC will select the better fitting model….
BUT this won’t always select the model that predicts the best
SO we can use other measures, such as ROC curves, when our model goal is to predict well