Exam Review
Lecture 9
Dr. Elijah Meyer
Duke University
STA 199 - Spring 2023
February 10th, 2023
Checklist
– Clone exam review repo
Exam Highlights
– This is an individual exam
– With the exception of major emergencies, late submissions will not be accepted. A last-minute technical issue is not a major emergency.
– Turn in via PDF. If you fail to do so, we will grade your latest commit and issue a penalty
– Include appropriate labels, titles, etc. when making any plot
– Clarification questions are welcome. Debuging is not
– Cite any code you obtain outside of the course materials
– Pull, Commit, Push often (after every question)
– Look at what’s rendered!
Goals
– group_by
– mutate
– summarize
– Pivots
– Joins
– Relationship Discussion
Join vs Pivot
– Join (2 data sets) vs Pivot (1 data set)
– Many ways to join data sets vs Two ways to pivot data
Join practice
– In the exam-review.qmd, join our two fake data sets using left_join, right_join, and full_join. Take note of the differences in the resulting output.
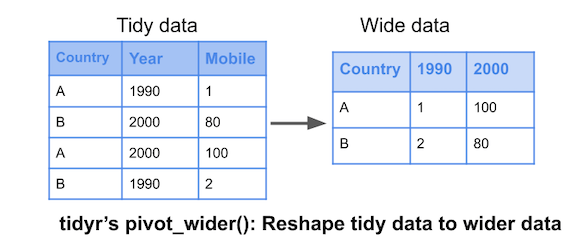
Pivot Wider and Longer
With a wide structure, each person (observational unit) has one observation (row) and a separate column contains data for each measurement. With a long structure, each person (observational unit) has multiple observations; one measurement per row.
![]()
Steps (Long to Wide)
– What values should make new columns?
– Where do the values should go in those new columns?
![]()
The Code
babies |>
pivot_wider(
names_from = Year,
values_from = Mobile
)
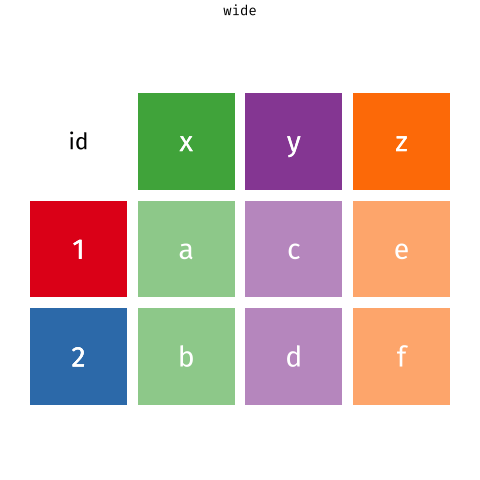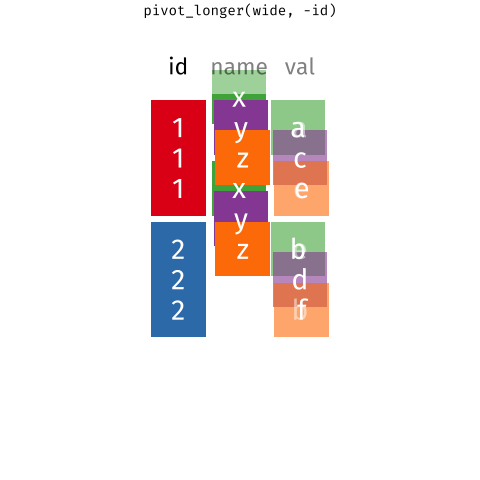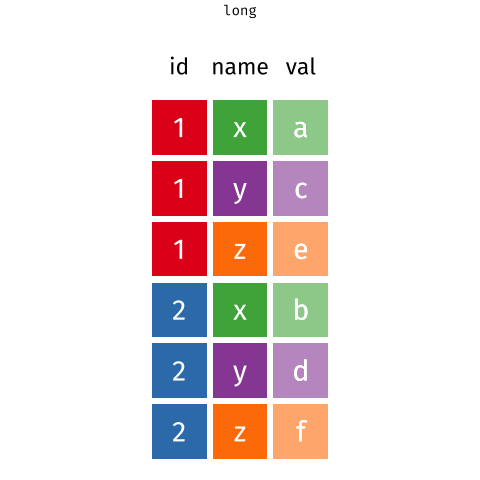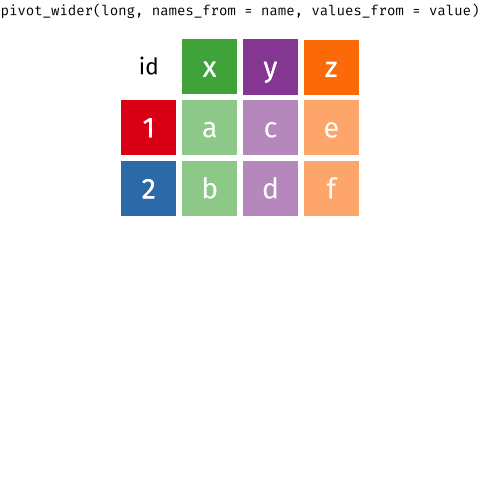
Steps (Wide to Long)
– What columns should be values?
– What should we name that column?
– What should we name the new column for the “left over” values?
The Code
babies |>
pivot_longer(
cols = !(Country),
names_to = Year,
values_to = Mobile
)
In action
![]()
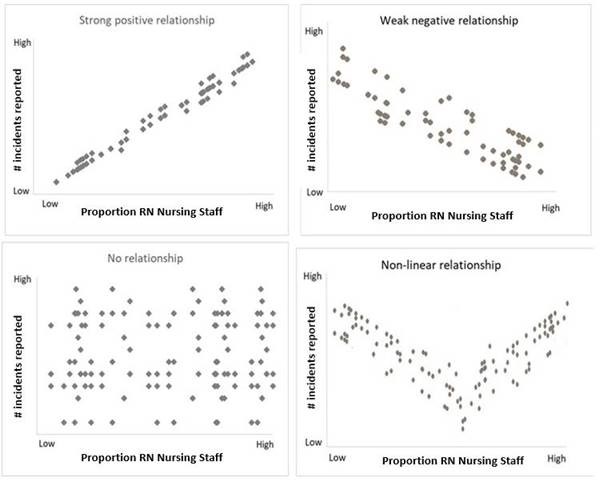
Relationships
How we talk about graphs….
Scatterplot
![]()
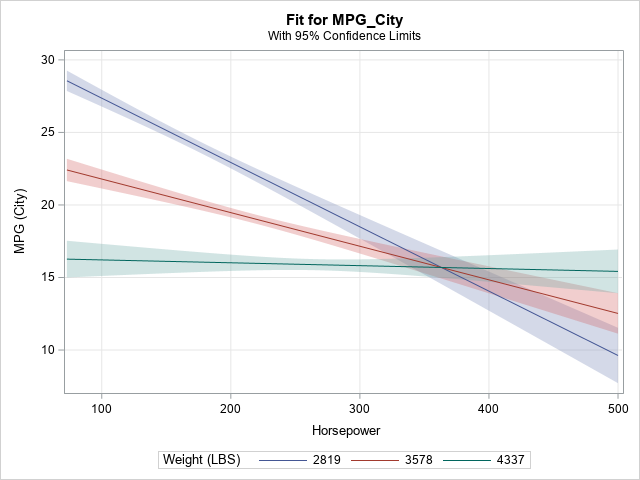
Interactions
![]()
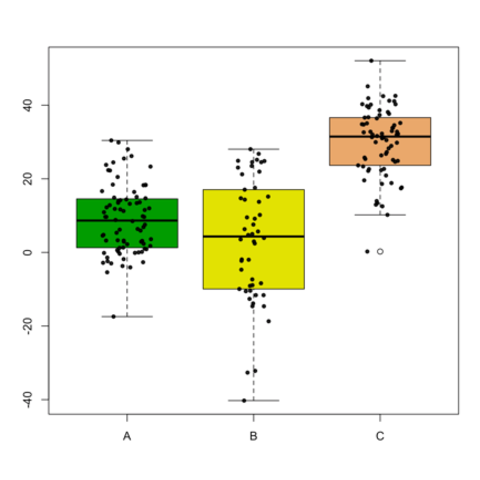
Boxplot
![]()
Barplot
![]()
ae-7