This is our significance level that we use to help make decisions and conclusions for a hypothesis test. It also is the probability of making a type 1 error
Why would a researcher choose to have a larger or smaller \(\alpha\) value?
The larger the alpha, the less evidence you will need to reject the null hypothesis. However, the larger the alpha, the more likely it is to reject the null hypothesis incorrectly.
Iris Data
The Iris Dataset contains four features (length and width of sepals and petals) of 50 samples of three species of Iris (Iris setosa, Iris virginica and Iris versicolor). A sepal is the outer parts of the flower (often green and leaf-like) that enclose a developing bud. The petal are parts of a flower that are the pollen producing part of the flower that are often conspicuously colored. The difference between sepals and petals can be seen below.
The data were collected in 1936 at the Gaspé Peninsula, in Canada. For the first question of the exam, you will use this data sets to investigate a variety of relationships to learn more about each of these three flower species. The data set is prepackaged in R, and is called iris.
# A tibble: 2 × 2
Species m
<fct> <dbl>
1 setosa 5.01
2 versicolor 5.94
Save your response below as estimate
#define your difference in means as your estimate belowestimate<--0.93
To “standardize our statistic”… we need to divide by the standard error. The standard error of the different in sample means can be calculated as follows:
Below, define each piece of the standard error accordingly
Write an appropriate scope of inference in the context of the problem below:
Random Sampling did not happen
Random Assignment did not happen
We do not have random sampling, so any results we find are generalized to our sample or a similar sample.
There is an association between Species and Sepal length in our sample or a similar sample.
Two Categorical Variables: Case study: CPR and blood thinner
Cardiopulmonary resuscitation (CPR) is a procedure used on individuals suffering a heart attack when other emergency resources are unavailable. This procedure is helpful in providing some blood circulation to keep a person alive, but CPR chest compressions can also cause internal injuries. Internal bleeding and other injuries that can result from CPR complicate additional treatment efforts. For instance, blood thinners may be used to help release a clot that is causing the heart attack once a patient arrives in the hospital. However, blood thinners negatively affect internal injuries.
Here we consider an experiment with patients who underwent CPR for a heart attack and were subsequently admitted to a hospital. Each patient was randomly assigned to either receive a blood thinner (treatment group) or not receive a blood thinner (control group). The outcome variable of interest was whether the patient survived for at least 24 hours.
`summarise()` has grouped output by 'group'. You can override using the
`.groups` argument.
# A tibble: 4 × 3
# Groups: group [2]
group outcome props
<fct> <fct> <int>
1 control died 39
2 control survived 11
3 treatment died 26
4 treatment survived 14
Now create an appropriate visualization of these data below.
cpr|>ggplot(aes(x =group , y =..count..))+geom_bar(aes(fill =outcome), position ="stack")
Warning: The dot-dot notation (`..count..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(count)` instead.
Next, explain how one dot (observation) is created on the permutation null distribution used to test our hypotheses…
Assuming that group is independent of outcome, we permute outcome to new values of group. Next, we calculate the new proportions of died for each permuted group. We subtract these difference in proportions. That is a dot!
Now, calculate the p-value below:
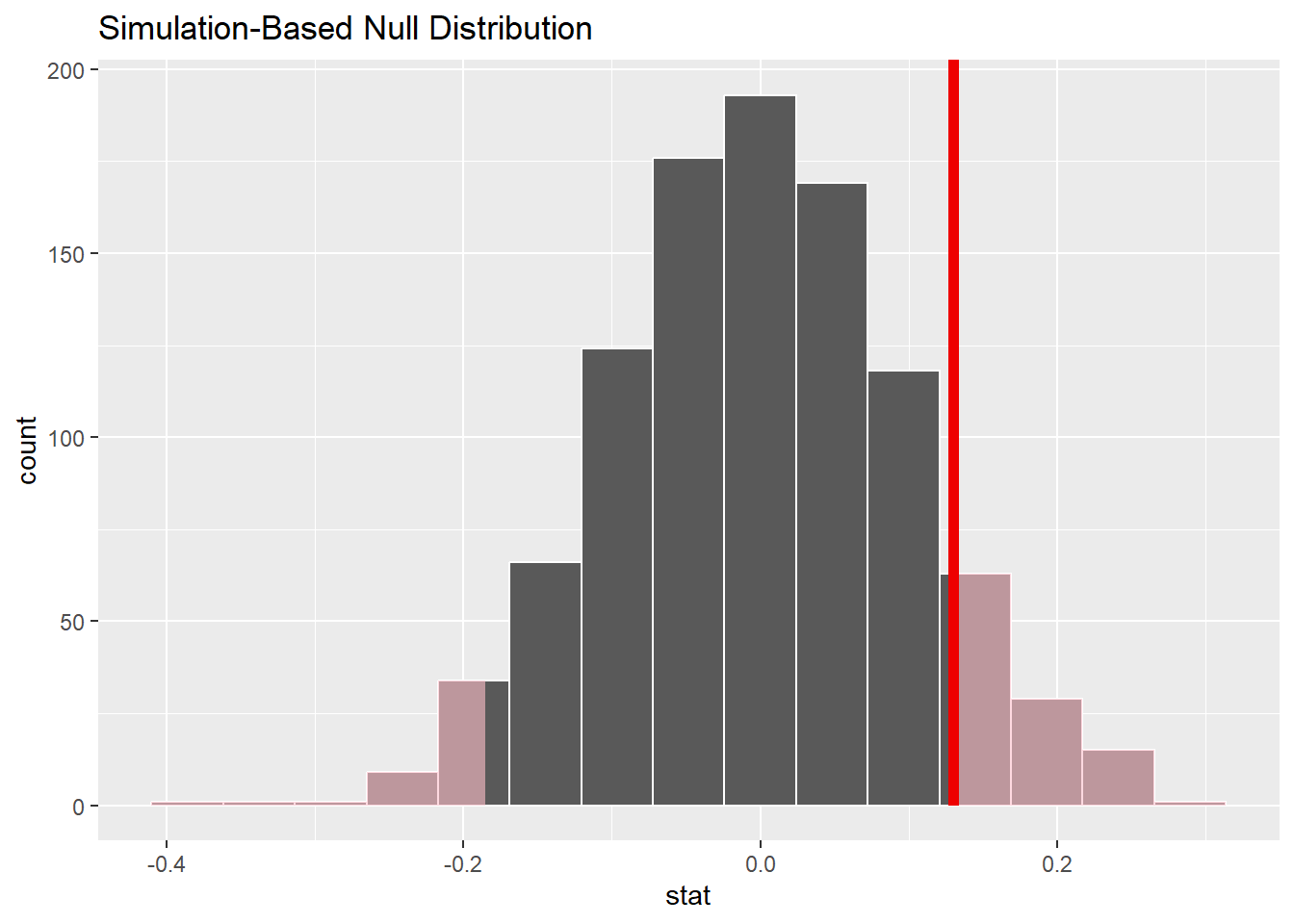
set.seed(1234)null_dist<-cpr|>specify(response =outcome , explanatory =group , success ="died")|>hypothesize(null ="independence")|>generate(reps =1000, type ="permute")|>calculate(stat ="diff in props" , order =c("control", "treatment"))
visualize(null_dist)+shade_p_value(obs_stat =.13, direction ="two-sided")
null_dist|>get_p_value(obs_stat =.13, direction ="two-sided")