Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Rows: 82 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): country
dbl (3): capture, aquaculture, total
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 245 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): country, continent
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Global aquaculture production
The Fisheries and Aquaculture Department of the Food and Agriculture Organization of the United Nations collects data on fisheries production of countries.
Goal: Our goal is to create a visualization of the mean share of aquaculture by continent.
– Fill in NA values with appropriate continent information
joined_fish<-joined_fish|>mutate( continent =case_when(country=="Democratic Republic of the Congo"~"Africa",country=="Hong Kong"~"Asia",country=="Myanmar"~"Asia", TRUE~continent))
– Add a new column to the joined_fish data frame called aq_prop. We will calculate it as aquaculture / total.
Demo: Using your code above, create a new data frame called fisheries_summary that calculates minimum, mean, and maximum aquaculture proportion for each continent in the fisheries data.
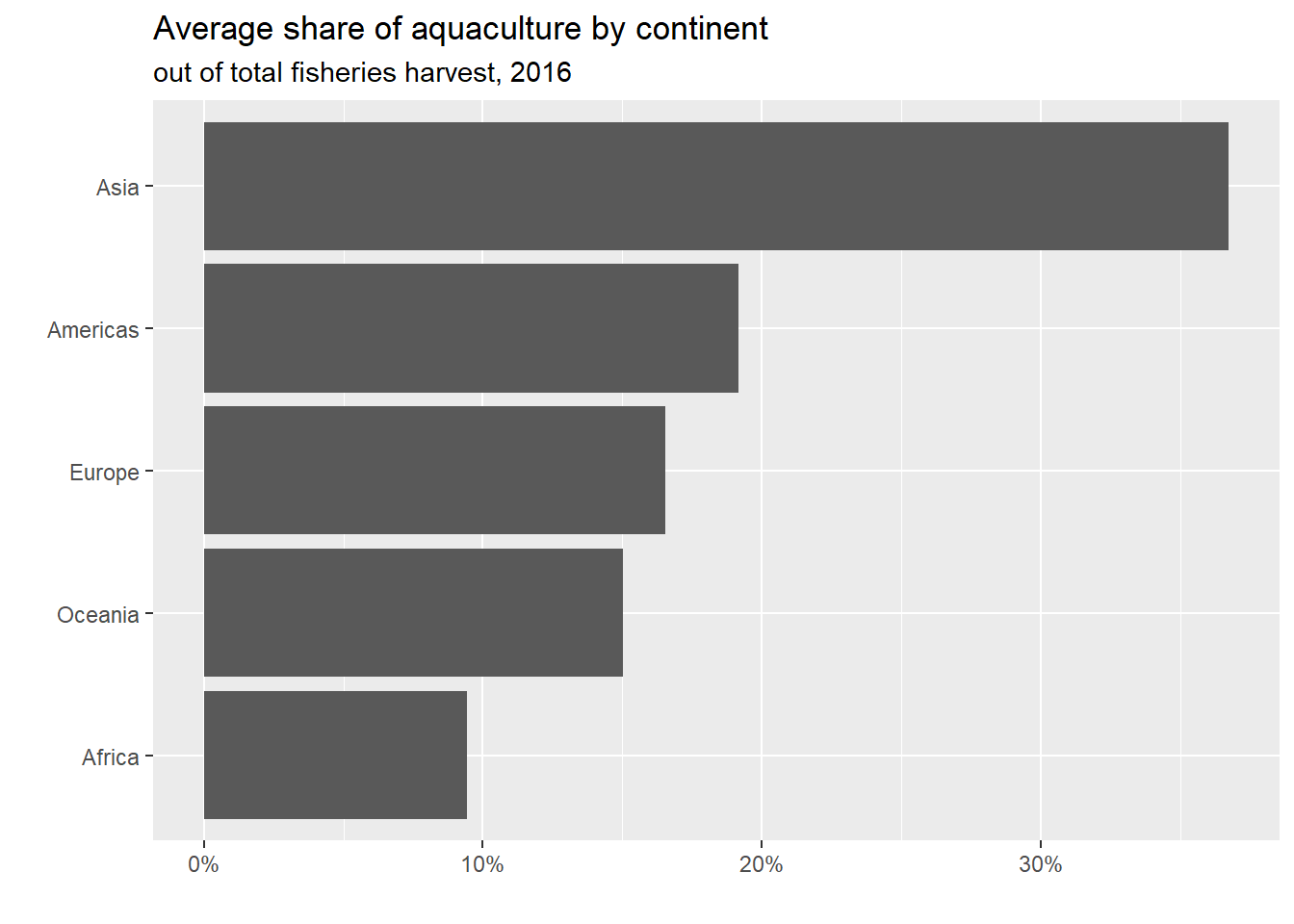
Demo: Recreate the following plot using the data frame fisheries_summary you have developed so far.
Hint: We use ftc_relevel to manually specify levels of a factor
We use fct_reorder to reorder a factor based on another variable
We can use functions in R to create more appropriate axis labels (such as adding %s). We can do this through the following: scale_x_continuous(labels = scales::) and scale_y_continuous(labels = scales::). See documentation here and create axis labels that match the picture.
fisheries_summary|>ggplot(aes(y =fct_reorder(continent, mean_aq_prop), x =mean_aq_prop))+geom_col()+labs( title ="Average share of aquaculture by continent", subtitle ="out of total fisheries harvest, 2016", y =" ", x =" ")+scale_x_continuous(labels =scales::percent)
Pivot Practice
Run the following code below. Are these data in long or wide format? Why?
x<-tibble( state =rep(c("MT", "NC" , "SC"),2), group =c(rep("C", 3), rep("D", 3)), obs =c(1:6))x
# A tibble: 6 × 3
state group obs
<chr> <chr> <int>
1 MT C 1
2 NC C 2
3 SC C 3
4 MT D 4
5 NC D 5
6 SC D 6
Pivot these data so that the data are wide. i.e. Each state should be it’s own unique observation (row). Save this new data set as y.
# A tibble: 6 × 3
state group obs
<chr> <chr> <int>
1 MT C 1
2 MT D 4
3 NC C 2
4 NC D 5
5 SC C 3
6 SC D 6
Pivot Practice 2
Let’s try this on a real data set.
The Portland Trailblazers are a National Basketball Association (NBA) sports team. These data reflect the points scored by 9 Portland Trailblazers players across the first 10 games of the 2021-2022 NBA season.
Rows: 9 Columns: 11
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Player
dbl (10): Game1_Home, Game2_Home, Game3_Away, Game4_Home, Game5_Home, Game6_...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
– Take a slice at the data. Are these data in wide or long format?
– Suppose now that you are asked to have two separate columns within these data. One column to represent Game, and one to represent Location. Make this happen below. Save your new data set as new.blazer
# A tibble: 90 × 4
Player Game Home Away
<chr> <chr> <dbl> <dbl>
1 Damian Lillard Game1 20 NA
2 Damian Lillard Game2 19 NA
3 Damian Lillard Game3 NA 12
4 Damian Lillard Game4 20 NA
5 Damian Lillard Game5 25 NA
6 Damian Lillard Game6 NA 14
7 Damian Lillard Game7 NA 20
8 Damian Lillard Game8 NA 26
9 Damian Lillard Game9 4 NA
10 Damian Lillard Game10 25 NA
# … with 80 more rows